Reinforement learning 4 - Policy-based
一、介绍
在前面的章节,我们介绍了基于价值的强化学习方式,它通过估计价值函数作为中间结果,然后利用确定的策略,比 …
在前面的章节,我们介绍了基于价值的强化学习方式,它通过估计价值函数作为中间结果,然后利用确定的策略,比 …
在前面两篇文章,我们大概介绍了基于价值方式的强化学习优化方法,比如 Q-learning 通过维护 Q-A 的 table 来不断执行策略获 …
基于价值的强化学习方式,我们的目标是学习一个价值函数,能够根据状态 $s$ 映射到对应状态期望的价值 …
强化学习是智能体通过采取动作与环境进行交互,获取奖惩及后续观测,进而学习动作策略的框架。
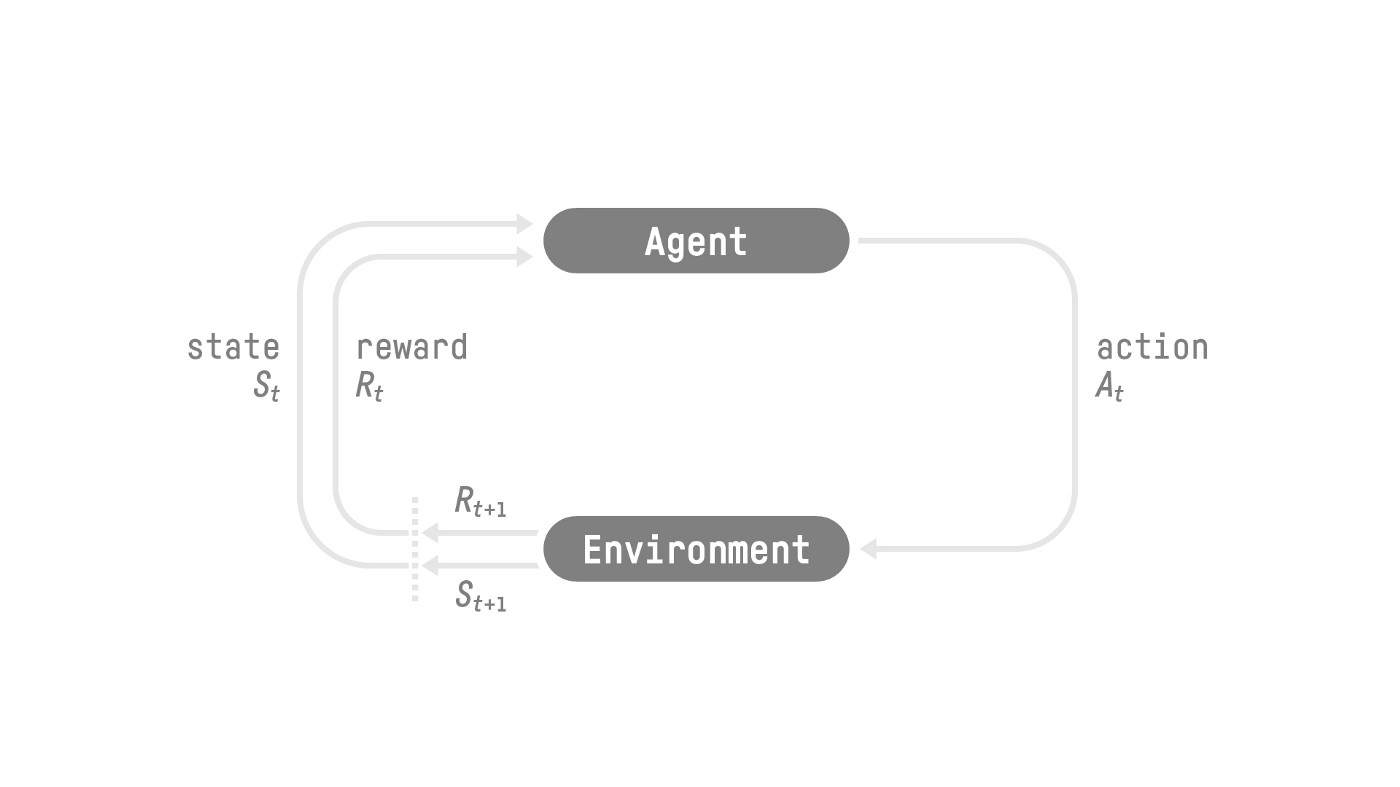
环境的观 …
随着 ChatGPT 的出现,研究人员对大语言模型 (Large Language Model) 的关注不断增加,针对它的方方面面展开研究。目前已经形 …
An summary of deep learning system.

一分钟了解一片论文系列,从框架图可以看出网络设计相对简洁,图像经过 Vision-encoder(比如 CLIP)之后,经过一个 MLP 将特征转 …
Sparse4D 可以理解为 Decoder Only 的检测框架,从 query 出发来检测目标,相比 DETR3D 来说主要是对 reference points 相关的优化。
特征部分来自图像经过 …
模型训练的第一步并不是一上来就开始写训练代码,而是先观察数据。要花费足够多的时间,查看上千帧图像来 …

Input