一、Deep Q-learning
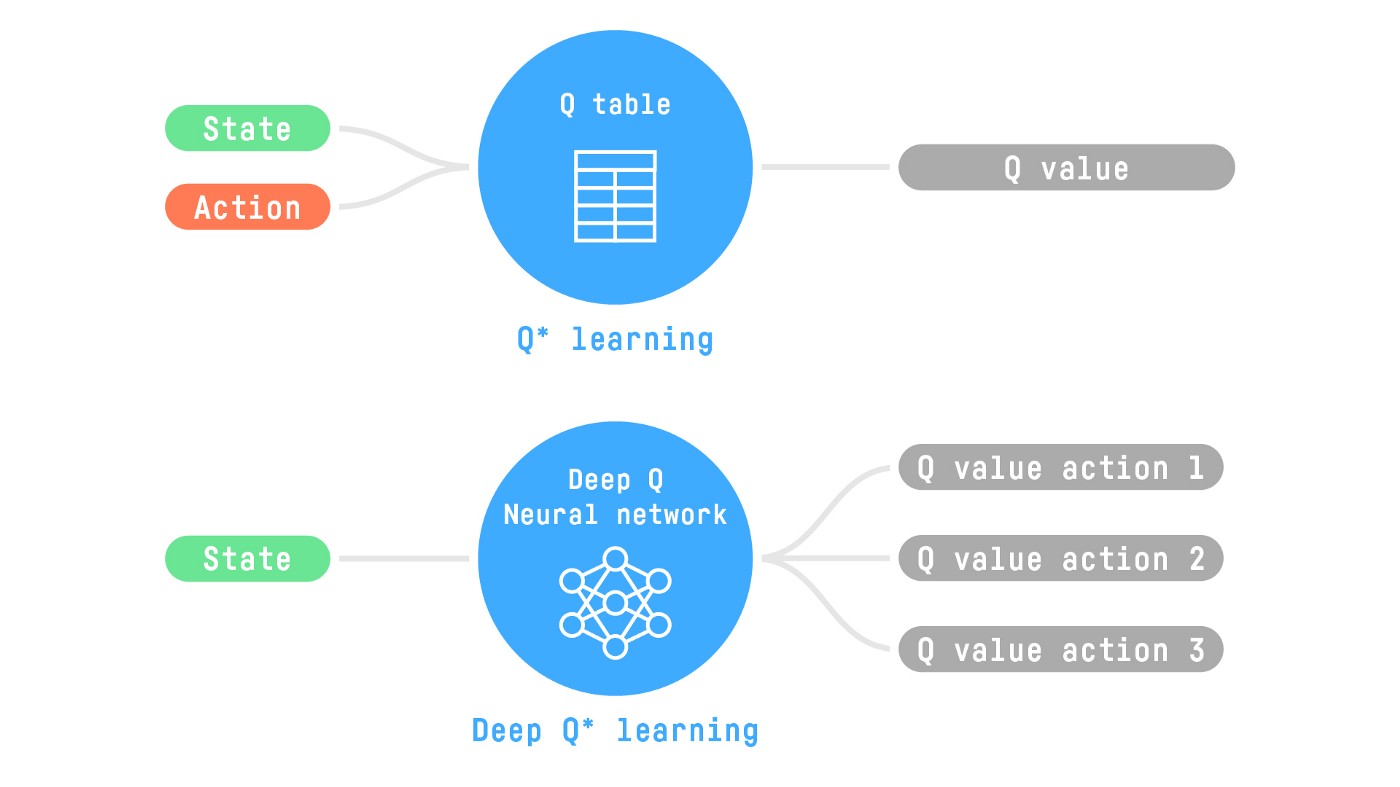
在前面两篇文章,我们大概介绍了基于价值方式的强化学习优化方法,比如 Q-learning 通过维护 Q-A 的 table 来不断执行策略获得反馈再更新价值,而这个方法只能限定在有限状态和动作。对于拥有极大数量状态的环境如何学习呢,下面介绍 Deep Q-learning。
Deep Q-learning 的目标是输入状态,通过深度学习网络学习每个 action 对应的 Q-value。不同的输入状态可以抽象成图像,网络输出是当前状态在不同 action 下的 Q-value,即时反馈加下一个状态所有 action 当中最高的 Q-value 作为监督信号,通过计算损失对网络参数进行梯度训练。
二、参考资料
- Hugging face: https://huggingface.co/learn/deep-rl-course/unit3/deep-q-algorithm