一、基础介绍
强化学习是智能体通过采取动作与环境进行交互,获取奖惩及后续观测,进而学习动作策略的框架。
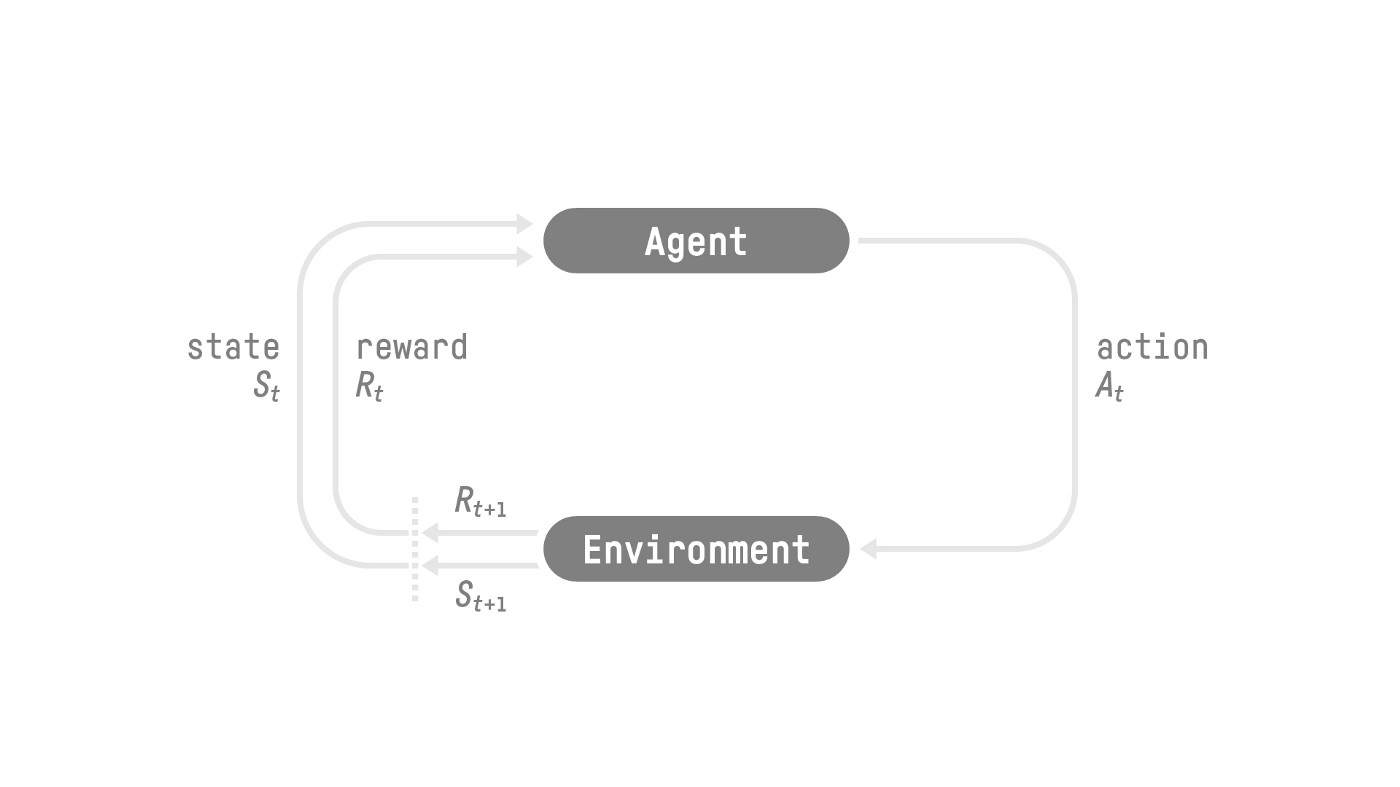
环境的观测类型可以分为两种:
- State: 世界的完整描述,没有隐藏信息
- Observation: 世界的部分描述
Agent 所采取的动作范围称为动作空间(Action),具体也可以按如下分类:
- 离散的,比如红白机游戏中的上下左右只有 4 个动作
- 连续的,比如真实的驾驶行为,转弯和加速大小都是实数连续值
奖惩以及折扣:
对于一个动作有即时反馈 $r$,则对于一个动作轨迹的累计奖惩可以按如下表示:$R(\tau)=r_{t+1}+r_{t+2}+...$, 但是对于轨迹来说,我们更关心眼前的奖惩,所以对于未来的反馈会增加一个折扣,最终的折扣累计奖惩形式如下: $$ R(\tau)=r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3}... $$
奖惩的设置非常重要,因为这是智能体学习的唯一反馈来源,这个也是强化学习要重点设计的。
动作策略:
策略(Policy)$\pi$ 是强化学习的学习函数,通过这个最优的策略,智能体能获取最大的奖赏。
二、机器学习方法对比
强化学习是一种机器学习方法,需要与监督学习和无监督学习做一下对比:
- 有监督学习: 给定成对的输入、输出,算法的目标是给定输入得到预想的输出,学习的输出一般是人工标注的
- 无监督学习:只给定输入,算法学习数据的内部结构,比如图像对比学习使得网络能提取图像的本质特征
- 强化学习:算法/智能体与动态环境交互,通过环境反馈的奖惩进行学习,从而实现奖惩最大化的动作策略
个人的理解:
- 场景部分:有监督学习更偏向静态场景,给定输入给出最合理的输出;而强化学习包含与动态环境一系列交互的过程, 目标是最大化整个动作序列的奖励。
- 损失部分:监督学习是输出与标签的差异,强化学习的反馈一般是折扣累计奖惩,当然如果折扣系数为0, 每一步也只关注当前的即时反馈。这个也就引申到 LLM 中 SFT 和 RLHF/PPO 的训练方式。
三、策略的学习方式
3.1 Policy-based
直接学习策略 $\pi$ 本身,根据观测直接输出动作,即 $\pi(S)=a$,基于动作的奖惩优化策略本身。动作的输出可以是确定的,也可以是一个概率分布。
3.2 Value-based
价值学习方案是间接的学习哪个状态价值更高,然后采取动作达到一个更高的价值状态,所以 policy 是人工设定且固定的, 即按价值最高的方式行动。
具体介绍两种方法:
Q-learning: 通过维护一个 Q-table 来输出 (state, a) 对应的 Q value。可想而知,这种方法只适用于 状态和动作个数有限的场景,比如 2x3 网格的老鼠吃大米小游戏。
Deep Q-learning: 通过搭建一个神经网络,接受 state 输入,输出不同 action 的 Q value。这个方法 可以应用于大量状态的问题。
四、参考资料
- Hugging Face: https://huggingface.co/learn/deep-rl-course/unit1/what-is-rl
- 有监督学习、无监督学习和强化学习: https://en.wikipedia.org/wiki/Machine_learning